
![]()
Utku Kubilay ÇINAR
R ile Derinlemesine Zaman Serisi…
Zaman serileri modellemeleri ve zaman serileri 1900’lü yıllardan sonra bilim çerçevesinde büyük adımlar atmıştır. Dünya piyasalarında borsa ve emtia kurlarının gelişmesiyle zaman serilerinde modelleme yapmak ve tahminci yaklaşımlar gerçekleştirmek büyük bir sorun haline gelmiştir. Bilim insanları bu sorunu çözebilmek adına birçok araştırma yapmış ve yeni modeller geliştirmiştir.
Dünya genelinde finansla alakalı literatür incelendiğinde 1980’li yıllarda bilimsel araştırmalarda artış görülmektedir. Feinstein (1987), Scott (1991) ve Knight (1998) bu çalışmalardan bir kaçıdır. Ülkemizde İstanbul Menkul Kıymetler Borsası (İMKB), yeni adıyla Borsa İstanbul‘un açılışı ile 1980’li yılların ikinci yarısında zaman serileri ve öngörü modelleri (geleneksel yöntemler) önemini arttırmıştır. Yabancı sermayenin ülkeye girişi ve yapılacak yatırımların belirlenmesi ve programlanması için öngörü yapmak değerli hale gelmiştir.
21. yüzyılın başlarında geleneksel yaklaşımların yapmakta zorlandığı ve bazı zorlukların yaşandığı modellemelere yeni yaklaşımlar yeni metotlar eklenmiştir. Yapay sinir ağları ile zaman serileri modellemesi yapılması son on yılda büyük aşama kaydetmiş ve birçok ulusal ve uluslararası makaleler, bildiriler yayımlanmıştır. Günümüzde bilgisayar gücünün artmasıyla “Yapay Zeka Tabanlı” modeller / işlemler, geleneksel yöntemlerin yerine geçmiştir/geçmektedir.
Bu çalışmada zaman serilerinde geleneksel yöntemler ile makine öğrenmesi algoritmalarından Yapay Sinir Ağı modeli kıyaslanacaktır. Bu çalışmada amaç; veri setine uygun, en iyi tahmin edici modeli karşılaştırarak bulabilmektir. Buna ek olarak, geleneksel yaklaşımlar ile yapay sinir ağları (YSA) (Artificial Neural Networks) karşılaştırılacaktır.
ZAMAN SERİSİ
Her veri seti, zaman serisi değildir. Bir veri setinin zaman serisi olabilmesi için değerlerinin zamana bağlı olarak değişmesi gerekir. Örnek verirsek Borsa İstanbul’da işlem gören halka açık firmaların aldığı hisse fiyatlarının değerleridir. Bu değerler zamana bağlı olarak değişir. Borsada işlem gören firmaların hisse senedi fiyatlarının zamana göre değişmeseydi, bir önceki günün etkisi olmasaydı, bu veri seti zaman serisi özelliğini kaybederdi. Başka bir örnek verirsek; ülkemize gelen turist sayılarıdır. Turist sayısı hem zaman serisine bağlıdır hem de mevsimsel etki barındırır.
Zaman serisi dört parçadan oluşur. Bunlar; trend bileşeni, mevsim etkisi, düzensiz etki ve konjonktürel etkilerdir.
- Trend (Eğilim) : Özellikle borsada yaygın olarak kullanılan trend, finansal piyasaların gittiği uzun vadedeki yönü olarak adlandırılır. Örnek verirsek, bir firma bilançolarında yüksek satışlar yaparsa ve borçluluğu azalırsa o firmanın borsada hisse fiyatları uzun vadede yükselen trende girer yani her dip birbirinin üzerinde olur, böylece fiyat yükselen trende girmiş olur.
- Mevsim Etkisi : Zaman serilerinde mevsim etkisi, mevsimsellik etkisi (seasonality effects), mevsimlere göre zaman serisinin etkilerinin ve değerinin değişmesidir. Bazı zaman döngüleri, bazı zamanlara göre daha çok – az olabilir. Bir zaman serisinin, birbirini izleyen yılların aynı aylarında göstermiş olduğu aynı veya benzer dalgalanmalar, mevsimsel dalgalanmalar olarak ifade edilir (Atlas, 2000).
- Konjonktürel (Çevresel, Devrevi) Hareketler : Zaman serisinin trend doğrusu veya eğrisi etrafındaki uzun dönem dalgalanmalarına konjonktürel dalgalanmalar denir. İktisatta ve işletmecilikte bolluk, durgunluk, depresyon ve yükselme devreleri konjonktürel dalgalanmalar olarak adlandırılır (Atlas, 2000).
- Rassal (Düzensiz) Etki : Belli olmayan, geçici hareketlerle ortaya çıkan, hata terimi ile ifade edilebilen rassal olaylardır. Örneğin, savaş, doğal felaketler, don gibi beklenmeyen nedenlerin oluşturduğu değişimlerdir. Önceden tahmin edilemezler.
DURAĞANLIK
Bir zaman serisinde analizlere başlamadan önce kontrol edilmesi gereken durum, verinin durağan olup olmamasıdır. Zamanla varyansın ve ortalamanın sabit olması gerekir. Kısaca şöyle tanımlayabiliriz; zaman içinde varyansın ve ortalamanın sabit olması ve gecikmeli iki zaman periyodundaki değişkenlerin kovaryansının değişkenler arasındaki gecikmeye bağlı olup, zamana bağlı olmamasıdır.
Zaman serisi modeli yapmak istenildiğinde, üretilen stokastik sürecin zamana bağlı olarak değişip değişmediği incelenmelidir. Zamana göre değişen bir özellik varsa seri durağan değildir. Durağan olmayan zaman serilerinin matematiksel formatta bir model yazılması mümkün değildir.
Durağan olmayan veri setini durgun hale getirmenin farklı yollar vardır. Öncelikle verinin durağan olup olmadığını anlayabilmek için veriye Unit- Root testleri (Birim Kök Analizi) yapılır. Eğer p-istatistik değeri anlamlı ise verimiz durağan değildir yani birim kök vardır denir. Verimizi analiz etmeden önce kontrol etmemiz gereken durağanlık analizinde, veriyi durağan hale getirmek için birinci dereceden farklar (farkın alınması yöntemi, method of differencing) alınarak veri seti durağan hale getirilir. Tekrar Unit-Root Testi yapıldığında aynı sorun devam ediyorsa ikinci dereceden farklar alınır buradaki amaç daha yüksek otokorelasyonlar söz konusu ise, bu etkiyi azaltmaktır.
Eğer veri setiniz, durağan değilse hemen birinci dereceden farklar alınmamalıdır. Şu unutulmamalıdır ki, durağanlık – trend – mevsimsel etkiler bunlar verinin karakteridir. Verinin bize söylediklerini kaçırmadan, karakterini anlamalıyız. Durağan olmayan veride farklar alma yöntemine geçmeden önce mevsimsel etki, trend etkisi ve yapısal kırılma gibi durumlar kontrol edilmeli, eğer bunlar mevcutsa arındırılmalıdır. Bu işlemlerden sonra da devam ediyorsa farklar alınması yöntemine gidilmelidir.
Durağanlık ve mevsimsellik incelendikten sonra Box-Jenkins modeller grubunda hangi model tipinin uygun olacağına karar verilir. Durağan model grubunda AR(p), MA(q) ve ARMA(p, q) durağan olmayan model grubunda ARIMA(p, d, q) ve mevsimsel model grubunda ARIMA( p, d, q) (P, D, Q) tiplerinden uygun olan belirlenir (Özmen, 1986).
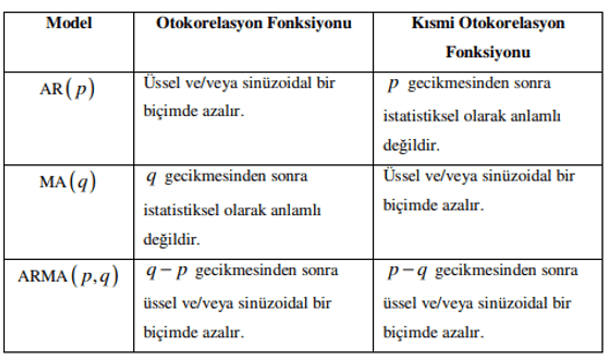
Durağan modellerde anakütle ACF ve PACF Hareketleri (Otokorelasyon ve Kısmi Otokorelasyon);
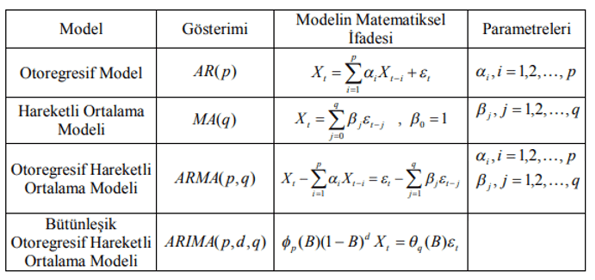
Modele ilave edilen yeni bir açıklayıcı değişkenin açıklayıcılık gücü ne kadar düşük ise, modelin AIC veya SBC değeri yükselir. Ln(T) değeri 2’den daha yüksek olduğundan, SBC, AIC’den daha tutumlu model seçecektir çünkü ilave olan açıklayıcı değişkenin marjinal maliyetinin AIC’e göre SBC’in ki daha yüksektir.
En uygun model belirlendikten sonra yapılması gereken bir başka konu ise modelin uygunluğunun sınanmasıdır. Model uygunluk sınaması farklı çeşitlerde yapılabilir. Öncelikle parametre değerleri yerine konarak tahmin değerleri bulunmaya çalışılır. Sonra bu tahmin değerleri için hata değerleri incelenir. Literatürde kabul görmüş, hangi veri setlerine hangi analizler uygulanması önerildiği aşağıdaki tabloda belirtilmiştir.
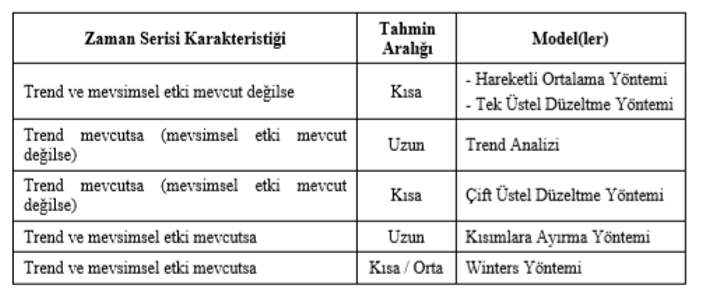
Tabloda görüldüğü gibi zaman serilerinde verinin karakterine göre yöntem seçimi yapılmalıdır. Her zaman serisinin kendine özgü karakteri vardır yani bazıları durağandır (genellikle durağan olmaz), bazıları mevsimsel etki barındırır, bazılarında ise trend etkisi vardır ya da hepsi birden. Eğer veri setinde mevsimsel etki ve trend etkisi yoksa kısa vadede tahmin yapılacaksa en uygun modeller hareketli ortalama yöntemi ve tek üstel düzeltme yöntemidir ya da trend ve mevsimsel etki mevcutsa ve kısa-orta vadeli tahmin yapılacaksa winters yöntemi modelini kullanmak gerekir. Bu modellerin arasında seçim yapmak istenirse burada da model seçme ölçütleri kullanılır MSE, RMSE, MAPE, MSE, AIC, SBC gibi kriterlere bakılarak seçim yapılır ve en uygun model belirlenir.
VERİ SETİMİZ
30 Mart 2003 ile 30 Eylül 2018 gününe kadar olan çeyreklik yani 3 ayda 1 olmak üzere toplam 63 gözlemden oluşmaktadır (30.03.2003 – 30.09.2018). Veri setimiz 3 ayda 1 olmak üzere bankaların bilançolarında yazan toplam mevduat kalemleridir ve zamana göre değiştiğinden zaman serisi verisidir. BIST 100 de işlem gören ve halka arz edilmiş 10 bankanın toplam mevduatlarıdır. Veri setine Kamuoyu Aydınlatma Platformu (KAP) üzerinden ulaşabilirsiniz.
UYGULAMA
Hadi Biraz Kodlayalım.
Uygulamada Kullanacağımız Kütüphaneler (Pokemonlar)
library(tidyverse) # Veri Manipülasyonu
library(readr) # Veriyi yükleme
library(stringr) # Veri Manipülasyonu
library(fpp2) # Zaman serisi Modeli
library(ggplot2) # Veri Görselleştirme
library(scales) # İstatistiksel Ölçümler
library(tseries) # Zaman serisi Modeli
library(data.table)
library(lubridate)
library(forecast)
library(neuralnet) # Yapay Sinir Ağları Modeli
options("scipen"=100, "digits"=4) # Veri setinde değerlerin tam yazılması için yazılan komutVeri Manipülasyonu
Veri setini bankaların bilançolarından “Mevduatlar” kalemindeki değerleri alarak oluşturdum. Oluşturduğum CSV dosyasında analizlere hazır hale getirmem için bazı dönüşümler ve zaman serisi olarak ayarlamam gerekiyor. Aşağıda ki kod dizininden inceleyebilirsiniz.
veri <- read_delim("veri.csv",
";",
escape_double = FALSE,
trim_ws = TRUE)
options("scipen"=100, "digits"=4) # Hücrelerdeki değerler tam yazılsın diye digit ayarı yaptım.
veri <- as.data.frame(veri)
veri[,2:length(veri)] <- apply(veri[,2:length(veri)],
2,
as.numeric)
veri[1:11,2:64] <- round(veri[1:11, 2:64])
names(veri)[2:64] <- names(veri)[2:64] %>%
str_replace_all("/", "-")
library(data.table)
setcolorder(veri,c("Bankalar", "2003-03", "2003-06", "2003-09", "2003-12", "2004-03",
"2004-06", "2004-09", "2004-12", "2005-03", "2005-06", "2005-09", "2005-12", "2006-03",
"2006-06", "2006-09", "2006-12", "2007-03" , "2007-06", "2007-09", "2007-12", "2008-03",
"2008-06", "2008-09", "2008-12", "2009-03", "2009-06", "2009-09", "2009-12", "2010-03",
"2010-06", "2010-09", "2010-12", "2011-03", "2011-06", "2011-09", "2011-12" , "2012-03",
"2012-06", "2012-09", "2012-12", "2013-03", "2013-06", "2013-09", "2013-12", "2014-03",
"2014-06", "2014-09", "2014-12", "2015-03", "2015-06", "2015-09", "2015-12", "2016-03",
"2016-06", "2016-09", "2016-12", "2017-03", "2017-06", "2017-09", "2017-12", "2018-03",
"2018-06", "2018-09"))
toplam_mevduat <- veri[11,2:length(veri)]
veri <- add_rownames(veri, "Tarih")
veri <- as.data.frame(veri)
veri$YKBNK <- as.numeric(as.character(veri$YKBNK))
veri$ISCTR <- as.numeric(as.character(veri$ISCTR))
veri$QNBFB <- as.numeric(as.character(veri$QNBFB))
veri$ICBCT <- as.numeric(as.character(veri$ICBCT))
veri$GARAN <- as.numeric(as.character(veri$GARAN))
veri$AKBNK <- as.numeric(as.character(veri$AKBNK))
veri$SKBNK <- as.numeric(as.character(veri$SKBNK))
veri$DENIZ <- as.numeric(as.character(veri$DENIZ))
veri$VAKBN <- as.numeric(as.character(veri$VAKBN))
veri$HALKB <- as.numeric(as.character(veri$HALKB))
veri$Toplam_Mevduat <- as.numeric(as.character(veri$Toplam_Mevduat))
veri$AKTIFTAHVIL <- as.numeric(as.character(veri$AKTIFTAHVIL))
library(lubridate)
veri$Tarih <- paste0(veri$Tarih,
"-",
"30")
veri$Tarih <- ymd(veri$Tarih)
toplam_mevduat <- ts(data = veri$Toplam_Mevduat,
frequency = 4,
start = c(2003,01),
end = c(2018,03))
egitim_veri <- ts(toplam_mevduat[1:47], # Veri setimizi % 75 Eğitim, % 25 Test olarak bölelim
frequency = 4,
start = c(2003, 01),
end = c(2014, 03))
test_veri <- ts(toplam_mevduat[48:length(toplam_mevduat)],
frequency = 4,
start = c(2014, 04),
end = c(2018, 03))
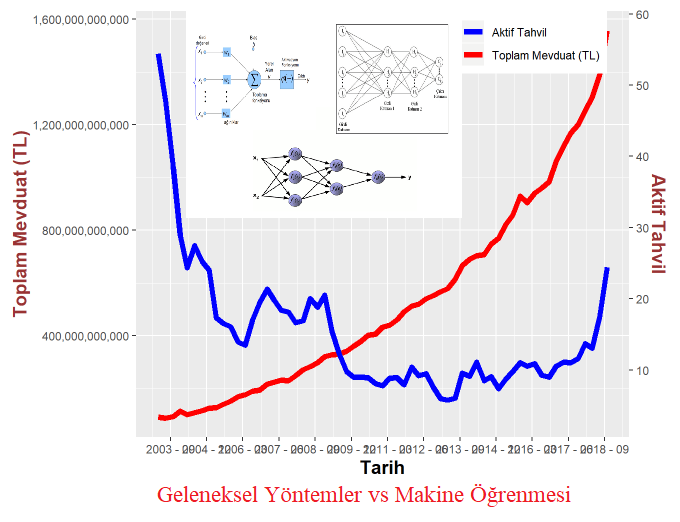
Veri setimizin görselini inceleyelim
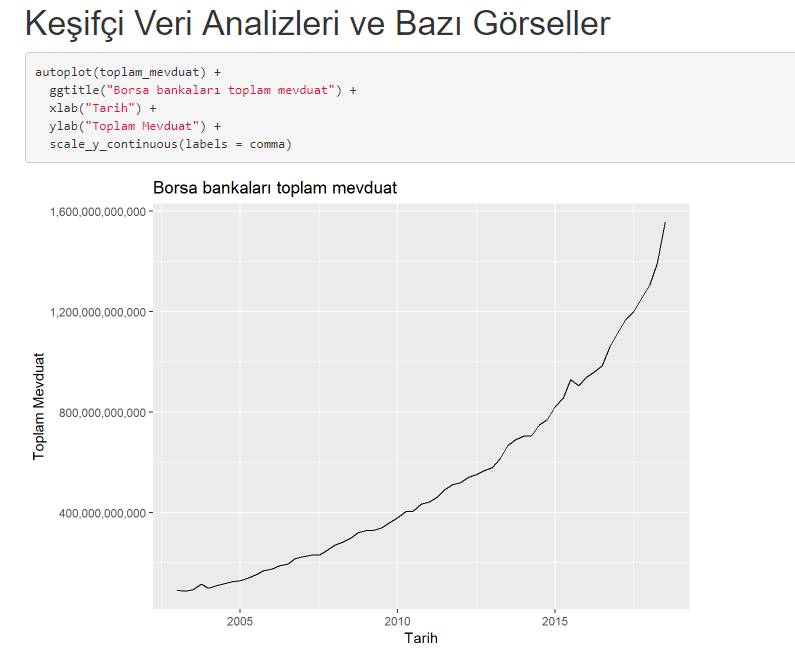
Veri setimiz toplamsal artıyor gibi görünüyor (Additive). Ayrıştırma işleminde (decomposition analizinde) de toplamsal olduğu görülüyor. Veri görüldüğü üzere son yıllarda ciddi bir artış olduğu hissediliyor.
p <- ggplot(veri,
aes(x = Tarih))
p <- p + geom_line(aes(y = Toplam_Mevduat,
colour = "Toplam Mevduat (TL)"),
cex = 2)
p <- p + geom_line(aes(y = AKTIFTAHVIL*27000000000,
colour = "Aktif Tahvil"),
cex = 2)
p <- p + scale_y_continuous(labels = comma,
sec.axis = sec_axis(~./27000000000,
name = "Aktif Tahvil"))
p <- p + scale_colour_manual("", values = c("blue", "red"))
p <- p + labs(y = "Toplam Mevduat (TL)",
x = "Tarih",
colour = "")
p <- p + scale_x_date(labels = date_format("%Y - %m"),
date_breaks = "15 month")
p <- p + theme(legend.position = c(0.8, 0.95),
plot.title = element_text(color="red",
size=14,
face="bold.italic"),
axis.title.x = element_text(color="black", size=14, face="bold"),
axis.title.y = element_text(color="#993333", size=14, face="bold"))
p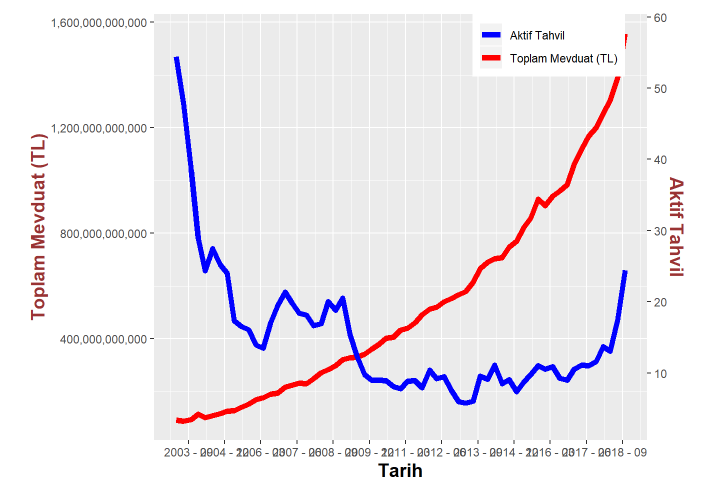
Toplam mevduat ile Aktif Tahvil (Piyasanın fiyatlandırdığı faiz oranı) aralarında ters bir ilişki var. Fakat son yıllarda bu durum tersine dönmüş gibi. Faiz çok büyük artış göstermesine ve toplam mevduat değerimiz de artmış.
corrplot::corrplot(cor(veri[,2:13]),
diag = TRUE,
order = "hclust",
tl.pos = "td",
tl.cex = 0.5,
method = "pie",
type = "upper")
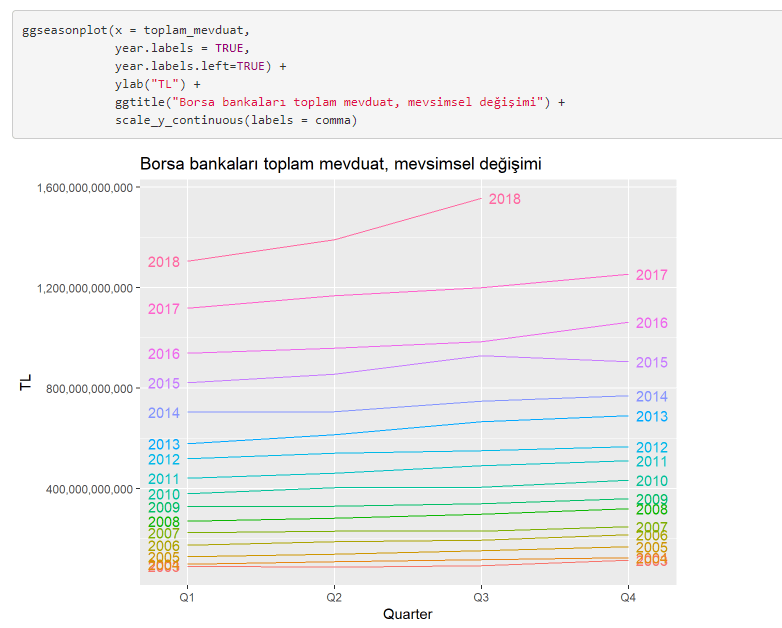
Grafikte Yıllar ve Çeyrekler bazında mevsimsel hareketlilik gösterilmektedir. Grafikler incelendiğinde belli bir patern olmadığı görülmektedir yani mevsimsel bir ilişkinin varlığından söz edilemez (ya da çok az bir etkisi var (Q3 dönemi). Uygulamanın ilerleyen kısımlarında Canova and Hansen testi ile inceleyeceğiz ve test sonucunda mevsimsel etkinin olmadığını gördük).

Bu grafikte dönemler bazlı toplam mevduat değerinin değişimi görülebilir. Grafikte de görüldüğü üzere Q3 döneminde varyansın diğer dönemlere göre fazla olduğu görülebiliyor. Aynı zamanda Q3 döneminde ortalama değerin daha yüksek olduğu görülebiliyor. Volatile(varyans) 3. dönemde yüksekken, 4. çeyrekte kısmen daha az olduğu farkediliyor.
Otokorelasyonlar için incelenmesi gereken faydalı bir grafik.
gglagplot(toplam_mevduat) +
ggtitle("Gecikmeler")+
scale_y_continuous(labels = comma)+
scale_x_continuous(labels = comma)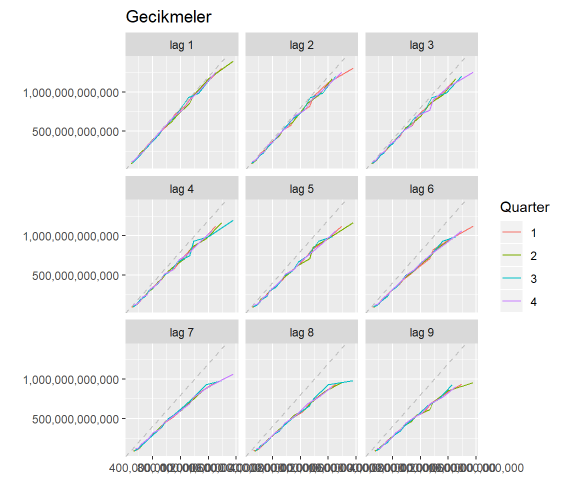
Otokorelasyon, bu saçılma grafiğindeki değerlerin (çizgilerin) korelasyonlarıdır.
ggAcf(toplam_mevduat, lag.max = 60) +
ggtitle("Otokorelasyon Fonksiyonu Grafiği")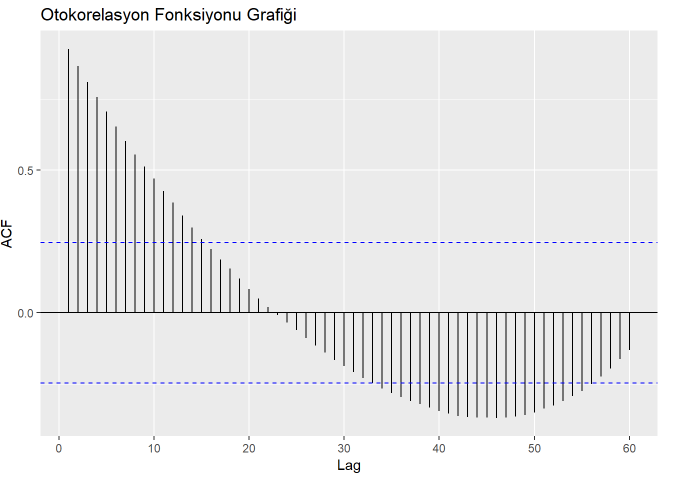
Veri setimizde ciddi otokorelasyon problemimiz olduğu görülüyor.
Mevsimsellik ve Trend incelemesi
decomposedRes <- decompose(x=toplam_mevduat)
stl_ts <- stl(toplam_mevduat,
s.window = "periodic")
plot(decomposedRes, lwd = 2) # Belli bir Trend olduğu net görülüyor. Deterministik bir
trendin varlığı olabilir. Kuşkulanmamız gereken konu durağanlık için ACABA VERİYİ
TREND DURAĞAN HALE GETİRMELİ MİYİZ ?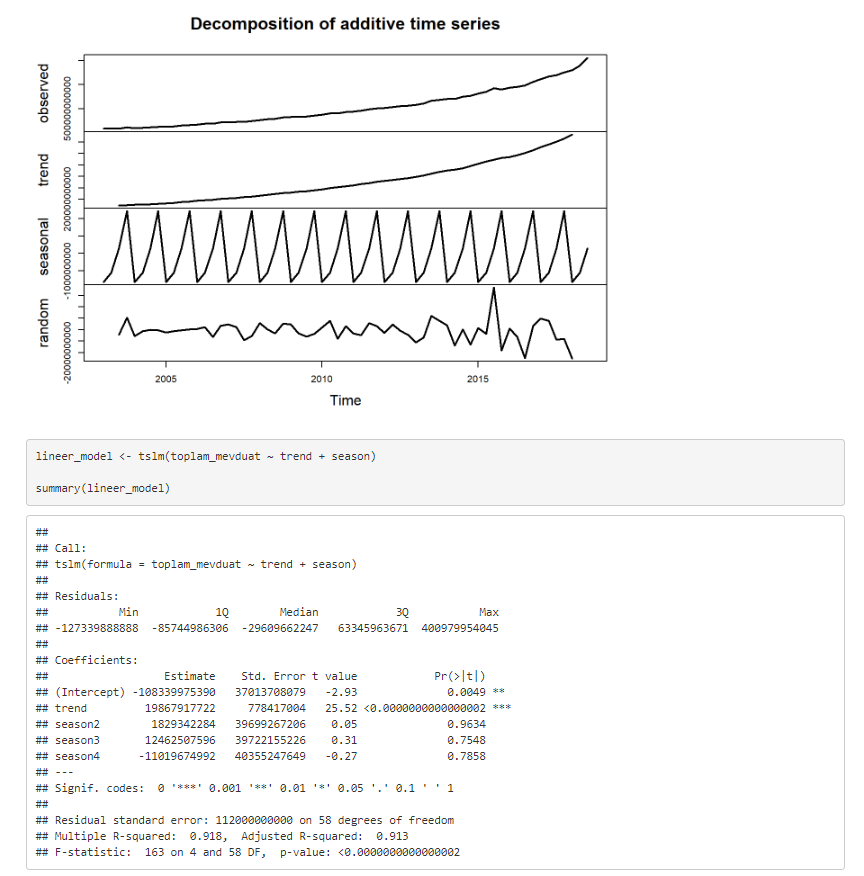
Mevsimel etki söz konusu değildir ve trend anlamlı (p istatistik değerinden bu hipotezleri kurabiliyoruz). Fakat verimizde Otokorelasyon olduğu için R kare ve t istatistiğine güvenmemeliyiz. Bu durum bize yol gösterici olabilir ama veride otokorelasyon olduğu için bu değerler araştırmacıyı yanıltabilir (R kare değeri yüksek, t istatistikleri düşük çıkabilir).
Geleneksel Yöntemlerde Zaman Serisi modeli kurulması için gerekli varsayımlar vardır. Bunlar;
- Kalıntılar arasında otokorelasyon olmamalıdır.
- Kalıntıların ortalaması sıfır olmalı.
- Kalıntıların varyansı sabit olmalı.
- Kalıntılar normal dağılmalı.
- Durağan olmalı
checkresiduals(lineer_model, test = "BG")
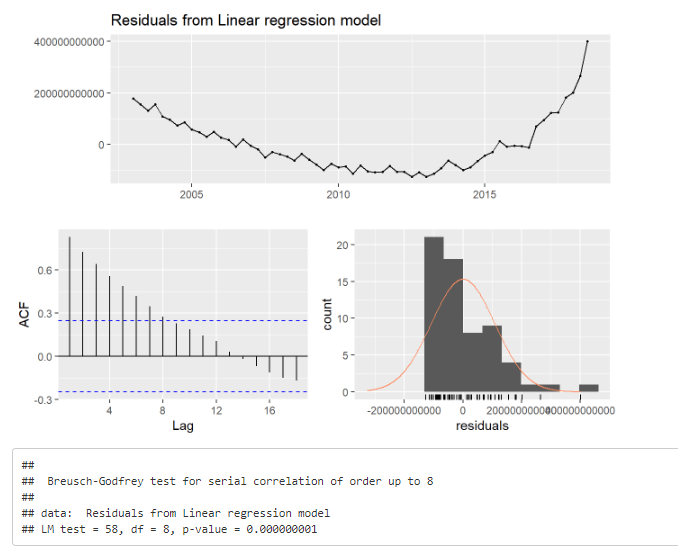
Görüldüğü üzere hiçbir varsayımımız sağlanmıyor. Model kurulamaz böyle bir durumda. Durağanlığı inceleyelim. Normalde analizlere başlamadan önce sırayla yapılması gereken işlemler şöyledir;
- Mevsimsel Etki
- Trend
- Yapısal Kırılma
- Durağanlık
Trend Durağan Veri
Veri setini durağanlaştırmak için direk birinci dereceden farklar alınmamalı. Sebebi ise, veri setinin bize söylediği bilgileri kaçırmamalıyız. Verinin karakterini bozmadan, alabildiğimiz tüm bilgileri almalıyız. Bu sebeple öncelikle mevsimsel ve trend bileşenlerinden arındırılmalı, bu işlemlerden sonra da veri seti durağan değilse birinci dereceden farklar alınmalı.
Öncelikle trend bileşeninden arındıralım.
trend <- stl(toplam_mevduat, s.window = "periodic")$time.series[,2] detrend <- toplam_mevduat - trend checkresiduals(detrend) # Varsayım kontrolü

Varsayımlarımız sağlanıyor ve ADF testi (Augmented Dickey-Fuller Test) ile verimizin durağan olduğu sonucuna varıyoruz. Artık modellenme kısmına geçilebilir. Ardından bazı kontroller yapılmıştır.
Veri setini trend bileşeninden arındırdığımızda varsayımlarımız sağlanıyor. Veri setimizi % 75 Eğitim, % 25 test verisi olarak ayıralım.
egitim_veri <- ts(detrend[1:47], # Veri setimizi % 75 Eğitim, % 25 Test olarak bölelim
frequency = 4,
start = c(2003, 01),
end = c(2014, 03))
test_veri <- ts(detrend[48:length(detrend)],
frequency = 4,
start = c(2014, 04),
end = c(2018, 03))
plot(detrend, type = "o", col = 1, lwd = 2, axes = F, xlab = "Trend Durağan Veri", ylab = "")
lines(test_veri, type = "o", col = 2, lwd = 2)
legend("topleft", xjust = 0.2,lty=1, col=c(1,2),
legend=c("Egitim Verisi", "Test Verisi"), lwd = 4, y.intersp = 0.3)
abline(reg=lm(detrend ~ time(detrend)),col = "blue")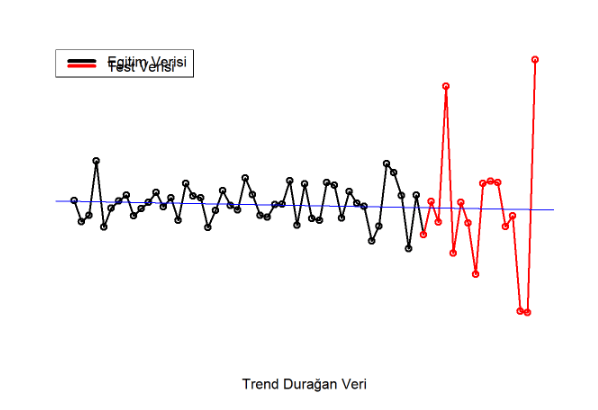
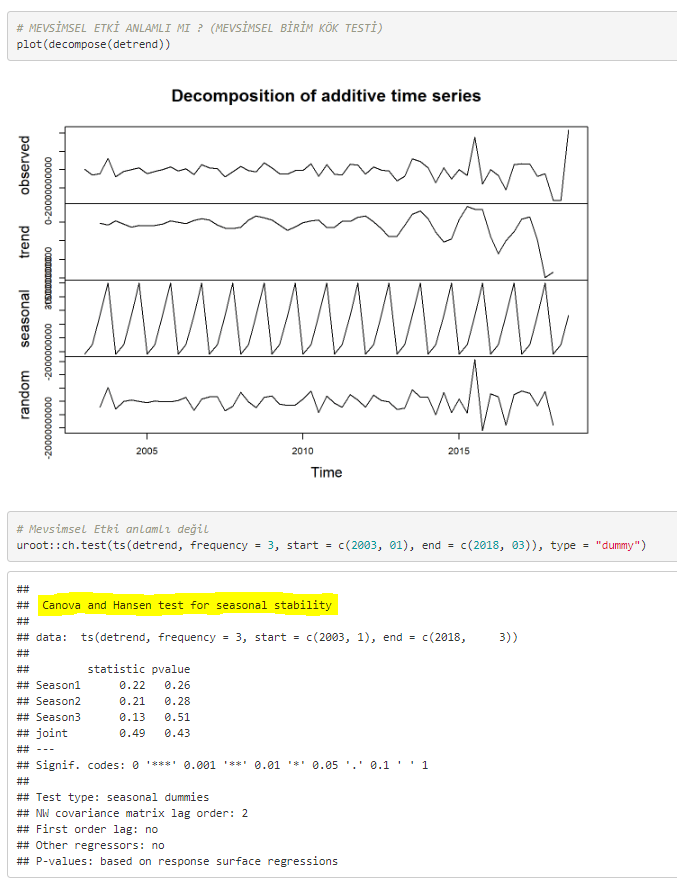
Decomposition görseli incelendiğinde, trend bileşeninde anlamlı bir hareket yok. Mevsimsel etki var gibi görünüyor. Bunun üzerine Canova and Hansen mevsimsel durağanlık testi yapıldı. Bunun üzerine mevsimsel etkinin anlamlı olmadığı görülmüştür.

Her şey varsayımlarımıza ve literatüre uygun. Artık model kurmaya başlayabiliriz.
meanf_tahmin <- meanf(egitim_veri,h=16)$mean # Ortalamalar Modeli
rwf_tahmin <- rwf(egitim_veri, h=16)$mean # Random Walk Forecast
rwf_tahmin_2 <- rwf(egitim_veri,drift = TRUE, h=16)$mean # Drift Model (Ürettiği Random Walk değeri ile veriyi dönüştürüyor)
snaive_tahmin <- snaive(egitim_veri,h=16)$mean
plot(detrend, main="Toplam Mevduat", ylab="", xlab="Tarih")
lines(meanf_tahmin, col=13, lwd=3 )
lines(rwf_tahmin, col=2, lwd=3 )
lines(rwf_tahmin_2, col=3, lwd=3 )
lines(snaive_tahmin, col=4, lwd=3 )
legend("topleft", xjust = 0.2 ,lty=1, col=c(13,2 ,3, 4),
legend=c("Mean method","random walk method","random walk Drift method", "Seasonal naïve method"),bty="n", lwd = 2, y.intersp = 0.3)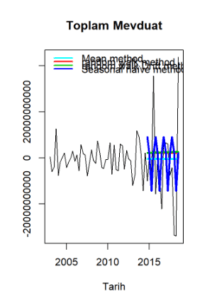
Görselden görüldüğü üzere Mevsimsel Naive Model en iyi sonucu veriyor.
Farklı bir model kuralım;
# Kubik Model
egitim_veri %>%
splinef(fan = T, lambda = "auto", method = "gcv") %>%
autoplot(xlab = "Kubik Model") +
ggtitle("")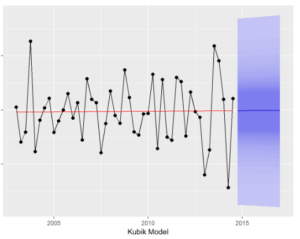
f_Cubic <- splinef(egitim_veri, h = 16) accuracy(f_Cubic, test_veri)

Model hatalarımız. Üstel Düzleştirme Yöntemi ile bir model kuralım;

accuracy(forecast(fit_ets,16), test_veri)

Üstel Düzleştirme Yöntemi kullanarak oluşturduğumuz modelin tahminlerini çizdirdiğimizde oluşan grafiğimiz;
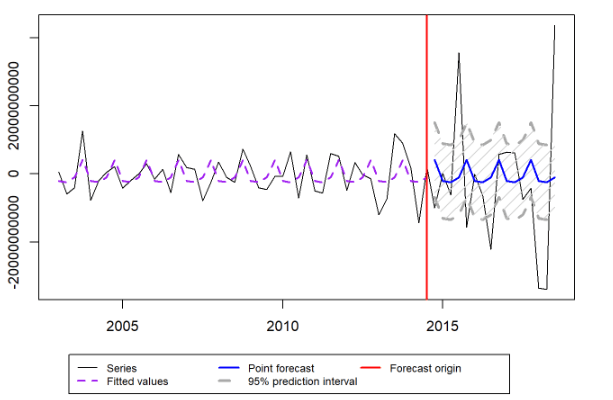
Arima Modelimiz;

accuracy(forecast(arima_model, h=16), test_veri)

Görüldüğü üzere ARIMA modeli daha başarılı gözüküyor. Yapay Sinir Ağları modeli oluşturalım ve sonuçları kıyaslayalım. 2 gizli katmanlı bir model oluşturduğumuzda;


Görüldüğü üzere Yapay Sinir Ağları yöntemi kullanılarak oluşturulan modelimiz daha başarılı tahminler üretti. Başarı kriteri olarakta MAPE (Ortalama Mutlak Yüzde Hata) kriteri seçilmiştir.
Önemli Not: Yapay Sinir Ağlarında hyperparameter ayarlaması kısmen yapıldı fakat diğer modellerde yapılmadığı için hataların farkı çok oldu. (Hyperparamater değişimleri ile diğer modellerde ortalama 15-20 puan azalmıştır)
Yapay sinir ağları modelleri, mevsimsel etkiler yansıtılmamış olsa bile diğer modellerden üstün performans sağlamakta, ek olarak mevsimsel etkilerin yansıtılması durumunda da performansını daha da artırmaktadır. Bunca üstün özelliklerine rağmen, modelin kurulum ve kullanımının oldukça basit, açık ve esnek olması, yapay sinir ağlarının tahmin yöntemi olarak pek çok alanda kullanımını gittikçe yaygınlaştırmaktadır. Problemin yapısına uygun olarak kurulmuş ve eğitilmiş yapay sinir ağı, günümüzde kullanılan birçok tahmin metodundan çok daha iyi sonuçlar vermektedir.
Çalışmada, Box – Jenkins, hareketli ortalama yöntemi, basit üstel düzleştirme ve makine öğrenimi Yapay Sinir Ağları algoritmaları ile karşılaştırılmıştır ve en yüksek performanslı yöntemin Yapay Sinir Ağları ile oluşturulan model olduğu görülmüştür. Bu sonuçlar daha önce yapılan benzer çalışmalar ile benzerlik taşımaktadır. Literatür incelendiğinde görülmüştür ki “Melez Yöntem” ile daha da iyi tahminler söz konusudur. Çalışma önerisi olarak LSTM yöntemleri ile zaman serisi çalışmak güzel olsa gerek 🙂 ?
Varsayımlarınızın sağlanması dileğiyle,
Veri ile kalın, Hoşça kalın..
KAYNAKÇA
- https://veribilimiokulu.com/yapay-sinir-aglari/
- https://harun-demir.com/2018/12/24/r-uzerinde-zaman-serisi-analizi-bolum-1-zaman-serisi-regresyonu/
- http://regitimmerkezi.com/r-ile-zaman-serileri-analizine-giris/
- http://uc-r.github.io/ts_exp_smoothing
- https://www.datascience.com/blog/introduction-to-forecasting-with-arima-in-r-learn-data-science-tutorials
- https://robjhyndman.com/talks/RevolutionR/6-ETS.pdf
- https://rpubs.com/tamu7804/kkkkkk
- Atlas, M., (2000), “İstatistik II: Çözümlü Örnekler”, Birlik Ofset Yayıncılık, Eskişehir.
- CINAR, U., K., (2018), “R ile Zaman Serisi Modelleri ve Yapay Sinir Ağları“, Yıldız Teknik Üniversitesi, İstatistik Bölümü, İstanbul.
- Enders, W., (1995), “Applied Econometric Time Series”, UK.
- Özdemir, Ö., (2008), “Zaman Serisi Modellemesinde Yapay Sinir Ağlarının Kullanımı”, Yüksek Lisans Tezi, Anadolu Üniversitesi Fen Bilimleri Enstitüsü, Eskişehir.
- Akgül, I., (2003), Geleneksel Zaman Serisi Yöntemleri, Der Yayınevi, 1. Basım: 7, İstanbul.
- Gujarati,D., N., (1995), ”Basic Econometrics”, 3. Basım:712, USA.
- Meyer, R., Krueger, D., (2005), “A Minitab Guide to Statistics”, 3. Baskı: 379. Pearson Yayınları, London, UK.
- Orhunbilge, N., (1999), Zaman Serileri Analizi Tahmini ve Fiyat İndeksi, Avcıol Yayıncılık, 1. Basım:141, İstanbul.
- Özek, T., (2010), “Zaman Serisi Modelleri Üzerine Bir Simülasyon Çalışması”, Yüksek Lisans Tezi, Selçuk Üniversitesi, Konya.
- Özmen, A., (1986), “Zaman Serisi Analizinde Box-Jenkins Yöntemi Ve Banka Mevduat Tahmininde Uygulama Denemesi”, Doktora Tezi, Anadolu Üniversitesi, Sosyal Bilimler Enstitüsü, Eskişehir.
- Fausett, L., (1994), “Fundamentals of Neural Networks: Architectures, Algorithms and Applications”, Prentice Hall.
- Hyndman, R., J., (2011), “Forecasting Time Series Using R”, Monash University, Avustralya.
- Karahan, M., (2011), “İstatistiksel Tahmin Yöntemleri: Yapay Sinir Ağları Metodu İle Ürün Talep Tahmini Uygulaması”, Doktora Tezi, Selçuk Üniversitesi, Konya.