
Çoklu Regresyon (Multiple Regression): Python ile Uygulama-2
![]()
Python ile çoklu lineer regresyon yazımıza devam ediyoruz. Geçen yazıda veri setini eğitim ve test olmak üzere ayırmıştık. Bu yazımızda makinemizi oluşturup eğiteceğiz. Yine scikit-learn linear_model kütüphanesinden LinearRegression sınıfını kullanacağız. Çoklu Lineer Modeli Eğitmek from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, y_train) Makinemizi (regressor) eğittik. Şimdi test edelim bakalım bize ne sonuçlar veriyor. Bunun […]
Çoklu Regresyon (Multiple Regression): Python ile Uygulama-1
![]()
Lineer Regresyon Notlarımıza devam ediyoruz. Bu yazımızda Python ile çoklu lineer regresyon uygulaması yapacağız. Teorik olarak ilk dört yazıda iyi kötü bir şeyler söyledik. Burada teoriden bahsetmeyeceğim. Öncelikle olayı anlamak adına elimizdeki veri seti nedir, kuracağımız model ile neyi çözmeyi amaçlıyoruz, hangi nitelikler hangi değişkenlerle eşleşiyor biraz bahsetmek istiyorum. Önce veri setimizi indirip Spyder’ın yakışıklı […]
Regresyon Modeli Kurmak
![]()
Lineer regresyonun bazı varsayımları var: Doğrusallık (linearity) Eşvaryanslık (homoscedasticity) Çok değişkenli normallik (multivariate normality) Hataların bağımsızlığı (independence of errors) Çoklu bağlantı yokluğu (multicollinearity) Bir lineer model kurmadan önce yukarıdaki varsayımların karşılandığını kontrol etmek gerekir. Regresyon Modeli Kurmak Lineer modelde iki farklı değişkenimiz vardı: ilki bağımlı değişken (hedef değişken – y) diğeri ise bağımsız değişken(ler)(predictors – […]
Basit Regresyon: R ile Uygulama
![]()
Lineer Regresyon serimize devam ediyoruz. Bu yazı bir öncekinin aynısı olacak ancak uygulamayı Python yerine R ile yapacağız. Çalışma dizninizi ayarlamayı unutmayın. Veri setine buradan ulaşabilirsiniz. R ile Veri Setini Yükleme dataset = read.csv(‘Kidem_ve_Maas_VeriSeti.csv’) Bağımsız değişkenimiz Kidem, bağımlı değişkenimiz Maas yukarıdaki tabloda görülmektedir. Gerçek hayatta da tecrübe ettiğimiz gibi kıdem arttıkça maaş da artar. Yani bağımsız ve […]
Basit Regresyon: Python ile Uygulama
![]()
Regresyon ile ilgili ikinci yazımıza devam ediyoruz. Bu yazıda teorik açıklamayı bitireceğiz ve Python ile basit bir lineer regresyon uygulaması yapacağız. Bir önceki yazımızda çoklu regresyon denklemimiz; Otomobil satış miktarı = β1TV Reklamı + β2Medya Reklamı + β3Radyo Reklamı + β0 şeklindeydi. Şimdi bu denkleme bir eleman daha ekliyoruz: hata terimi. Hata terimi bu modelde kaçırdığımız her ne […]
Veri Ön İşleme-3: Veri Setinden Eğitim ve Test Parçalarını Ayırmak (Python & R)

![]()
Veri ön işleme yazı dizimize devam ediyoruz. Bu yazıda ilk yazımızda kullanmaya başladığımız veri seti üzerinden uygulamalı olarak veri setimizi ne şekilde eğitim ve test verisi olarak parçalayıp yeni değişkenlere atayacağız onu göreceğiz. Böyle bir şeyi niçin yapıyoruz biraz bahsedelim:makine öğrenmesinde özellikle de denetimli (supervised) öğrenmede modelimizi veri ile eğitiriz. Yani veriden model öğrenir ve […]
Veri Ön İşleme-2: Kategorik Nitelikleri Dönüştürmek, Gölge Değişkenler Oluşturmak (Python & R)
![]()
Makine rakamları sever. Aşağıdaki veri setinde toplam dört nitelik ve 10 kayıt bulunmaktadır. Niteliklerden Age ve Salary nümerik; Country ve Purchased kategoriktir. Bu yazımızda kategorik nitelikleri nasıl nümerik hale getireceğimizi uygulamalı olarak göreceğiz. Veri setini indirip X ve y değişkenlerini oluşturmayı bir önceki yazıya havale ediyorum. Country Age Salary Purchased 1 Spain 27.0 48000.0 Yes 6 Spain […]
Veri Ön İşleme-1: Nümerik Nitelikler için Boş Değerleri Doldurmak (Python & R )
![]()
Bu yazımızda Python geliştirme ortamına veri setini nasıl indireceğiz ve indirdikten sonra bağımlı ve bağmsız değişkenlere nasıl atayacağımızdan bahsedeceğim. Mavi renkli kodlar komutları, siyah renkli kodlar sonuçları göstermektedir. Öncelikle temel kütüphanelerimizi indirelim: import numpy as np import matplotlib.pyplot as plt import pandas as pd Pandas read_csv metodu yardımıyla veri setimizi indirelim: Veri setine buradan ulaşabilirsiniz. […]
Spark MLlib Kullanarak Kümeleme Analizi

![]()
Makine öğrenmesi (machine learning) algoritmalarını kabaca ikiye ayırmak mümkündür: denetimli (supervised) ve denetimsiz (unsupervised). Her iki yöntemin de kullanım amaç ve yerleri farklı farklıdır. Bu yazımızda denetimsiz yöntemin en yaygın algoritması K-Ortalamaları (K-Means), iris veri setini ve Spark MLlib kütüphanesini kullanarak spark ile kmeans clustering örnek çalışma yapacağız. Burada amacım teorik olarak K-Ortalamalar yönteminin nasıl […]
Pandas Dataframe’i Hive Tablosu olarak Hadoop’a Kaydetmek

![]()
Sıkı durun uzun bir yazı olacak! Böyle bir macera ilk defa başıma geldiğinde çok zordur bu iş diyordum ancak öyle çok korkulacak bir şey olmadığını işi yaptıktan sonra fark ettim. Şimdi nereden çıktı bu konu? Ben veri temizliği için Pandas’ı çok seviyorum. Büyük veri setlerinin temizlemek istediğim yerlerini koparıp Pandas ile temizleyip tekrar yerine koyuyorum. Peki […]
Python Pandas ile Temel İşlemler

![]()
Bölüm 1 – Dosya Okuma & Sütun İsimlendirme Pandas; veri analizi ve veri ön işlemeyi kolaylaştıran açık kaynak kodlu bir kütüphanedir. Dil olarak Python kullanır. Pandas dağıtık işlemeye uygun değildir. Bu sebeple işleyeceğiniz verinin büyüklüğü makinenin kapasitesiyle sınırlıdır, özellikle de ana belleğin. Ben büyük veri setleri üzerinde işlem yaptığım için Pandas’ı çok fazla kullanamıyorum ancak […]
Python Listesinden Spark RDD ve Dataframe Oluşturmak

![]()
Zaman zaman Python listesinden PySpark Dataframe oluşturmamız gerekebiliyor. En azından benim gerekiyor. Bu kısa yazımızda bunu gerçekleştireceğiz. Önce 9 insanın aylık ücretlerini temsil eden Python listemizi oluşturuyoruz. Bu çalışmada Spark 1.6 kullanılmıştır. ucret =[2000.00,3750.00,1000.00,4800.00,4800.00,0.00,4800.00,0.00,14500.00] Python listesinden Spark RDD oluşturalım ucretRDD = sc.parallelize(ucret) Kontrol edelim ucretRDD.take(9) [2000.0, 3750.0, 1000.0, 4800.0, 4800.0, 0.0, 4800.0, 0.0, 14500.0] Şema […]
PySpark Dataframe İşlemleri
![]()
Bölüm 1 Bu yazımızda Spark’ın Dataframe’inden bahsedeceğim. Spark Dataframe (nedense Spark Tablosu diyesim var 🙂 ) yapısını ilişkisel veri tabanlarındaki tablolara benzetebiliriz; satırlar, sütunlar ve şema. Spark Dataframe; Python, R, Pandas vb. dillerdeki dataframe benzese de en büyük farkı dağıtık işlemeye uygun olmasıdır. Spark Tablosunu; ilişkisel veri tabanı tabloları, Hive tabloları, Spark RDD ler gibi birçok […]
Python SQL Server Bağlantısı

![]()
Hepimizin bildiği gibi en yaygın kullanılan veri tabanlarından birisi de Microsoft SQL Server’dır. Bu yazımızda veri bilimi çalışmalarında yaygın olarak kullanılan dillerden birisi olan Python ile MSSQL Server veri tabanına bağlanarak basit bir SELECT sorgusunu çalıştıracağız. Bu yazıyı hazırlarken kullandığım yazılım ve versiyonları şu şekildedir. OS: Windows 10 SQL Server: SQL Server 2012 Python: Python […]
Nedir Bu Iris Çiçek Muhabbeti?

![]()
Merhaba , veri bilimleriyle uğraşan arkadaşlar çoğu kez iris çiçeği ile temas kurmuştur. Bu işe ilk başladığımda ben de “Nedir bu çiçek muhabbeti?” diye anlamakta güçlük çekmiştim. Sonra olayı öğrenince “Haaa!, olay bu muymuş yahu” dedim. Bu işe yeni başlayanlar veya hala iris muhabbetini bilmeyenler benim gibi eziyet çekmeden olayı şipşak anlasınlar diye bu yazıyı yazıyorum. […]
Veri Madenciliğinin Sınıflandırılması

![]()
Veri madenciliği konusunda kafaları karıştıran konulardan biri de bir çok teknik, yöntem, algoritmanın ve modelin nasıl sınıflandırılacağına dairdir. Benim kafa bu konuda biraz karışık. Belli bir süredir bu konularla ilgilenmeme rağmen ne nerededir hala tam oturtamadım. Bu konuda Gökhan SİLAHTAROĞLU’nun sınıflandırmasını sizlerle paylaşacağım. Niye durduk yerde şimdi sınıflandırıyoruz? kimileri kabaca iki sınıfta topluyor: Denetimli (supervised) […]
Lojistik Regresyon ve K-En Yakın Komşu

![]()
Giriş Regresyon modelinde hedef değişkenin (bağımlı – y) nicel olduğunu biliyoruz. Ancak gerçek hayatta birçok durumda hedef değişken nicel değil nitel olabiliyor. Nitel değişken ikili (evet-hayır, içiyor-içmiyor, hasta-hasta değil) olabileceği gibi, kategorik (iyi-kötü-çirkin) de olabilir. Hatta bu kategorik değişken sıralı (ilk öğrenim – lise – üniversite) da olabilir. Bu şekildeki hedef nitel değişkenleri tahmin etmeye […]
Regresyon Notları
![]()
Bölüm 1 Lineer regresyon bir olayı, bir ilişkiyi açıklamak ve tahmin yürütmek için kullanılabilecek bir yaklaşımdır. Lineer regresyon ile bir bağımlı değişkeni (hedef değişken) etkilediğini düşündüğümüz bağımsız (predictor) değişkenleri kullanarak bir model kurarız. Bu modelle bağımsız değişkenlerin bağımlı değişkenimizi nasıl etkilediğini görebiliriz. Kurduğumuz modelle bağımsız değişkendeki değişimi ne kadar açıklayabildiğimiz ve modelin anlamlı olup olmadığını […]
R ile Normallik Testi
![]()
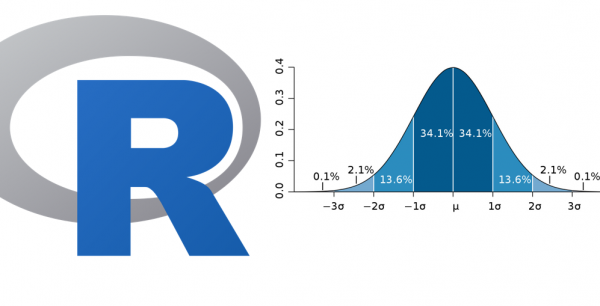
Veri seti üzerinde yaptığımız bir çok veri analizi verinin normal dağıldığı varsayımına dayanır. Veri analizine başlamadan önce verimizin normal dağılıma uygun olup olmadığına bakmamızda fayda var. Normallik kontrolü için yaygın olarak kullanılan testlerden birisi de Shapiro-Wilks testidir. Kullanımı oldukça basittir. Sadece numeric (numeric factor) verimizi argüman olarak shapiro.test(verimiz) fonksiyonuna ekliyoruz ekliyoruz. Verimiz: Verimizin numeric factor olduğunu […]
R ile Excel Tablosundan Veri Okumak, UTF-8 kodlamak

![]()
Bu yazımızda bir çok insanın sık kullandığı Excel tablosundan R çalışma ortamına veri almayı birlite uygulayacağız. Yüklemek için kullanılacak örnek dosya buradadır. Öncelikle xlsx paketini yüklememiz gerekir. İndirdiğimiz xlsx kütüphanesini çalışma ortamımıza yüklüyoruz. Paket indirmek ile paketi çalışma ortamına çağırmanın farklı şeyler olduğunu unutmayalım. Çalışma dizinimizi ayarlayalım (sizinki farklı olabilir) Çalışma ortamımızda bulunan Expertiz_Oz.xlsx dosyamızı utf-8‘e kodlayarak […]