

Merhaba bu yazımda büyük verinin en önde gelen teknolojisi Hadoop ve onun temel bileşenleri ve çevre bileşenlerinden kısa kısa bahsedeceğim. Amacım ne nedir ne işe yarar sorularına basit ve öz cevaplar vererek Hadoop ve ekosistemi hakkında genel bilgi vermektir.
Google’dan önce Doug Cutting ve Mike Cafarella webi crawl etmek ve indekslemek suretiyle bir arama motoru yapmaya kalktılar. Akılsızlar ne işiniz var böyle anlaşılmaz işlerle Eskişehir yolundan iki dönüm yer alıp üstüne yatsanız ömür boyu ihya olurdunuz. Neyse insanda akıl olmayınca… Fakat bu arkadaşlar ürettikleri içerikleri saklayabilecekleri ölçeklenebilir veri tabanı ve bu veriyi işleyecek farklı bir yönteme ihtiyaç duydular. İlişkisel veri tabanının aşırı katı ve taviz vermeyen tabiatı arkadaşlarımızın ihtiyacını görememiş. Niye? Pahalı, ölçeklenebilir değil, hataya ve arızalara karşı toleransı zayıf ve performansı beklendiği gibi değil. Yani arama kutusuna yazınca sonuçlar hemen gelsin hatta sen kelimeyi yazmadan tamamlasın. 2003 yılından itibaren Google tam da bu arkadaşların aradıklarını sağlayan iki önemli makale yayınladı birisi Google File System diğeri de MapReduce. Doug ve Mike bu yayınlardan esinlenerek Hadoop’u icat ettiler. Doug’un oğlunun oyuncağı olan küçük sarı file Hadoop ismini vermiş. Oyuncağın adı da bu teknolojinin adı olmuş. Önce Yahoo ve ardından birçok firma Hadoop’u kullanmaya başlamış. Bu esnada da zaten veri üretimi sürekli artıyor, internet gittikçe yaygınlaşıyor ve her geçen gün diskler ucuzluyor. Yani böyle manyak birşeye harbiden ihtiyaç var. Şimdi ise Hadoop büyük verinin en popüler şilahşörü. İlişkisel veri tabanı ve ACID mantığına dayalı bilgi sistemlerinde şimdiye kadar gelişip olgunlaşmış veri tabanı, güvenlik, yönetim, izleme, veri dönüştürme, serileştirme, veri aktarımı vb. tüm ihtiyaçlar Hadoop için tekrar oluşturulmaya başlanmış. Bugün Hadoop, gittikçe büyüyen tüm bu ihtiyaçların temelinde yer alan muazzam bir ekosistemin çekirdek teknolojisi durumundadır. Bu ekosistemi aşağıdaki sekiz ayrı kategoride incelemek mümkündür.*
- Temel Teknolojiler
- Veri Tabanları
- Serileştirme
- Sistem Yönetimi
- Analitik
- Veri Transferi
- Güvenlik ve Erişim Kontrolü
- Bulut ve Sanallaştırma
1. Temel teknolojiler
Hodoop’un en temelinde aslında Hadoop Distributed File System (HDFS) ve MapReduce bulunuyor. Ancak zaman içinde duyulan ihtiyaç ve geliştirmeler sonunda Hadoop versiyon 2 diye adlandırılan Yet Another Resource Negotiator (YARN) ve bellek kullanımı ile MapReduce hantallığını aşan Spark temel teknolojiler arasında yerini aldı diyebiliriz.
HDFS:
HDFS, Hadoop cluster verisinin depolandığı disk alanıdır. HDFS genellikle clusterı oluşturan sunucuların yerel disklerini kullanır. Ayrıca SAN vb. yöntemlerle erişim sağlayan pahalı depolama aygıtları gerektirmez. RAID de kullanmaz. HDFS geniş ölçekli büyük verilerde okuma yoğun operasyonları optimize eder. Aynı veriyi bir kaç kopya (varsayılan 3) tuttuğu için hata toleransı vardır. Yani her kopya farklı bir sunucuda olduğu için bir sunucu arızalansa bile veri kaybı olmadan Hadoop cluster işlemeye devam eder. HDFS’de ekleme vardır ancak güncelleme yoktur. İlişkisel veri tabanlarının aksine büyük veri güncellemeyi sevmez. Write once, read many (WORM) yapısındadır. Bu nedenle operasyonel işlemler (OLTP) için uygun değildir. En küçük veri parçacığı (data block) 64 veya 128 MB gibi büyük olunca sıralı ve büyük dosyalarını okumada oldukça başarılıdır. İlşkisel veri tabanı gibi bayt, kilobayt gibi kıl tüy işlerden hoşlanmaz. HDFS içinde veriyi fazla hareket ettirmeyi sevmez çünkü bu cluster içi ağ trafiği oluşturur. Çünkü cluster sunucuları birbirine kablo (tercihen fiber) ve ağ anahtarı (switch) ile bağlıdır. Bu sebeple veri olduğu yerde kalmaya eğilimlidir. Clusterı oluşturan sunucular ikiye ayrılır datanode ve namenode. Datanode işi yapan işçi, namenode ise işi planlayan ve dağıtan koordine eden diye düşünülebilir. Verinin metadatası da namenode sunucuda tutulur.
MapReduce:
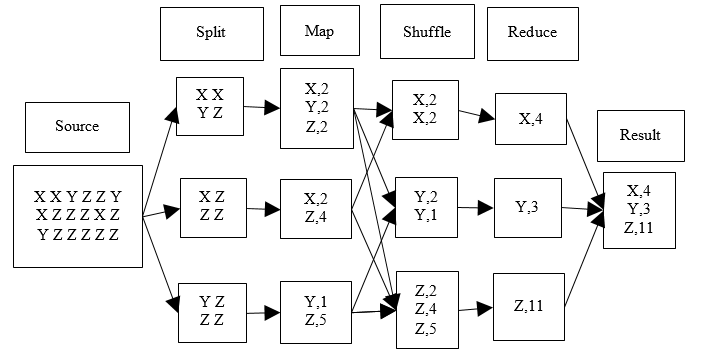
MapReduce Hadoop üzerinde uygulama geliştirmek için bir programlama çerçevesi, mantığı sunar. MapReduce temel olarak veriyi parçala, işçilere dağıt, herkes sonucunu yollasın kardeşim, al sana sonuç. MapReduce mantığını bir örnek üzerinde kabaca anlamaya çalışalım. Bir çuval karışık kuruyemiş olsun. Çuval içindeki her bir çeşit kuruyemişten kaç tane olduğunu hesaplamaya çalışalım. Mesela 29833 fındık, 44532 fıstık vb. Şimdi bu çuvalı bir insanın önüne koysak ve desekki say kardeşim ve bize her çeşitten kaç tane olduğunu söyle adam muhtemelen akşama kadar tırmalayacaktır. Ancak şöyle bir yöntemle saymaya kalksak. 20 kişi çağırsak bir kişi bir çuval kuruyemişi bunlara pay etse. Herkes önüne düşen 2,5 kg kuruyemişi cins cins ayırıp saysa ve sonucunu koordinatöre söylese. Koordinatör de 20 kişiden aldığı sonuçları toplasa. Alın size sonuç hem de çok daha kısa sürede. Dağıtık hesaplama var mi işin içinde var. Hız arttı mı? artı. İşte birinci örnek dağıtık hesaplamanın yapılamadığı tek sunuculu ilişkisel veri tabanı, ikincisi ise dağıtık hesaplamanın yapılabildiği MapReduce. Alın size big datanın temeli. Şimdi bir çuvalı saymaktan aciz arkadaşın önüne 50 çuval koysak ne olurdu. Adam muhtemelen sağlığını yitirirdi. Ancak 50 çuvalı 200 adamın önüne koysak ikinci model yine çalışır. İşte size ölçeklenebilirlik, işte size dağıtık hesaplama, işte size big data. Yukarıda anlattığımızın basit hali şema şeklinde aşağıda görülmektedir.
YARN:
YARN, Hadoop 2.0 ile gelen bir geliştirme çabasının sonucu. Yet Another Resource Negotiator. 202’de geldi bazen MapReduce 2.0 diyorlar. YARN MapReduce üzerinden kaynak planlamasını alarak veri işlemeden ayrıştırdı. Böylelikle MapReduce batch job ile streaming ve interaktif sorgular eş zamanlı çalışma şansını elde etmiş oldu. Yani diyebiliriz ki YARN Hadoop’un yeteneklerini genişleten ve Hadoop ekosisteminin merkezinde yer alan temel bir unsurdur. HDFS ve MapReduce’tan sonra üçüncü temel parça olarak yerini alıyor. YARN’dan önce Hadoop’un ölçeklenebilirliğinde de sıkıntılar oluşmaya başlamıştır. Yahoo’nun denemelerine göre 5.000 sunucu ve 40.000 görevde Hadoop tıkanıyordu. Ayrıca dinamik kaynak tahsisi de olmadığından cluster kaynakları görevler tarafından verimli bir şekilde kullanılamıyordu. Ayrıca başlangıçta sadece MapReduce için tasarlanmış olan Hadoop zamanla yeni programlama yaklaşımlarına da kucak açmak durumundaydı örneğin graph programming (Apache Giraph). Daha detaylı bilgi için IBM sayfasında güzel ve doyurucu bir yazı bulunuyor.
Spark:
MapReduce paralel programlamada çığır açsa da sonradan gelen bazı ihtiyaçlar ve teknolojik gelişmeler karşısında yetersiz kalmaya başladı. Özellikle iterasyon gerektiren veri madenciliği gibi bir alanda her seferinde ara sonuçları diske yazıp okuması performans sıkıntıları doğurdu. Bunlardan biri de çizge analizidir. Spark MapReduce’un buna benzer eksikliklerini gidererek esnek ve genel bir işleme motoru olarak ortaya çıktı. Özellikle ana belleği kullanarak MapReduce’dan onlarca kat daha fazla dağıtık veri işleyebilecek hale geldi. Bellek kullanımı gereksiz diske yama ve okumaları önlemektedir. Spark Hive ve Pig’in aksine MapReduce’un kullanımını kolaylaştıran birşey değildir. Aslında MapReduce’un birebir alternatifi ve rakibidir. Bazen Hadoop ile Spark rakip görülür ancak bu yanlıştır. Spark MapReduce için alternatiftir. Spark üç temel fikirden oluşur. RDD, transformasyon ve aksiyon. RDD dönüştürmek veya analiz etmek istediğimiz veriyi tutan soyut kaplardır. Transformasyon mevcut bir RDD’yi tadil ederek yeni bir RDD oluşturma işlemidir. Aksiyon ise RDD’yi işler, analiz eder ve istenen sonucu döndürür. Spark scala diliyle yazılmıştır. Ancak Python, Java dilleri için de API’si vardır.
* Sitto, Kevin, and Marshall Presser. Field guide to hadoop: an introduction to hadoop, its ecosystem, and aligned technologies. ” O’Reilly Media, Inc.”, 2015.