
Apache Spark SQL: CSV Okuma, Şema Oluşturma, Dataframe Üzerinde SQL Sorguları (Scala)

![]()
Merhaba, bu yazımızda Spark Dataframe oluştururken ve dataframe üzerinde veri keşfi yaparken kullandığım bazı işlemleri paylaşacağım. Basit bir yazı olacak ancak bunu önemsiyorum çünkü birçok insan veri yükleme esnasında sorun yaşıyor ve bir sürü zaman kaybediyor. Daha önce de buna benzer yazı yazmıştım ancak o zaman Spark1 kullanmıştım. Artık Spark2 var. Spark 2.0 sürümüyle birlikte […]
Linux Yetkilendirmeler (Linux Permissions)

![]()
Hepimiz Linux kullanırken permission denied gibi hatalar almışızdır. Bu tür hataları çözmek veya hataya baştan düşmemek için Linux’un kullanıcı, grup, sahiplik (owner) ve file mode kavramlarını iyi anlamalıyız. Bu yazımızda dosya modu (file mode) kavramı ve chmod ile file mode nasıl düzenlenir onu ele alacağız. Sonrasında örnekler yapacağız. Linux dünyasında bir kullanıcı bir dosya veya […]
Sık Kullanılan Linux Komutları: grep ve wc
![]()
Atatürk’ün bilim ile ilgili söylemiş olduğu sözlerden derleme yaparak bir metin dosyası içine topladık. Bu yazımızda kullanacağımız komutları bu örnek dosya üzerinde yapacağız. erkan@vm:~/lnx_kmtlari\$ nano ataturk_bilim_sozleri.txt Bilim ve fen nerede ise oradan alacağız ve ulusun her bireyinin kafasına koyacağız. Hayatta en hakiki mürşit, ilimdir. Her işin esas hedefine kısa ve kestirme yoldan varmak arzu edilmekle beraber, yolun […]
Sık Kullanılan Linux Komutları:Kopyalama, Taşıma ve Silme
![]()
Serinin bu yazısında temel linux komutlarından kopyalama, taşıma, silme işlemlerini göreceğiz Aynı anda birden fazla dizin yaratma erkan@vm:~\$ mkdir dir1 dir2 dir3 erkan@vm:~\$ ls -l total 191140 drwxrwxr-x 2 erkan erkan 4096 Eyl 16 07:07 dir1 drwxrwxr-x 2 erkan erkan 4096 Eyl 16 07:07 dir2 drwxrwxr-x 2 erkan erkan 4096 Eyl 16 07:07 dir3 Linux […]
Sık Kullanılan Linux Komutları: Genel Bilgiler
![]()
Kendim sıkça kullandığım Linux komutlarını bu yazıda derleyeceğim. Umarım sizlere de faydası dokunur. Komut satırında shell promptun solunda \$ varsa kullanıcı, # varsa superuser demektir. erkan@vm:~\$ exit exit root@vm:/home/erkan# Harddisk doluluk durumunu görmek için:df root@vm:~# df Filesystem 1K-blocks Used Available Use% Mounted on udev 1995360 0 1995360 0% /dev tmpfs 403528 11456 392072 3% /run […]
Bir Bakışta K-Fold Cross Validation

![]()
K-Fold Cross Validation, sınıflandırma modellerinin değerlendirilmesi ve modelin eğitilmesi için veri setini parçalara ayırma yöntemlerinden biridir. Bu yazımızda k-fold cross validation (k sayısı kadar çapraz doğrulama) yöntemini anlatmaya çalışacağım. Elimizde bin kayıtlık bir veri seti olsun. Biz bu veri setinin bir kısmı ile modelimizi eğitmek, bir kısmı ile eğittiğimiz modelimizin başarısını değerlendirmek istiyoruz. Basit yaklaşım; […]
Apache Oozie’yi Oluşturan Unsurlar

![]()
Bu yazımda Apache Oozie’yi oluşturan temel kavramlar ve bunlar arasındaki ilişkiden bahsedeceğim. O’Reilly tarafından basılmış Apache Oozie kitabının bu bölümünü okuyorum. Onu okurken aldığım notları sizinle paylaşacağım. Kitap, Mohammed Kamrul Islam ve Aravind Srinivasan adlı Oozie projesinde de görev almış iki yazar tarafından kaleme alınmış. Giriş Yahoo’da Hadoop kullanılmaya başladıktan sonra Hadoop görevleri daha karmaşık […]
Apache Oozie ile MapReduce Görevi Çalıştırma
![]()
Apache Oozie’ye daha önce basit bir giriş yapmış ve küçük bir java uygulamasını çalıştırmıştık. Bu yazımızda examples dosyası içindeki MapReduce görevini başlatacağız. examples klasörünü bulmayı ve lokal dizinde bir yere kopyalamayı şu yazıya bırakarak atlıyorum. Aşağıdaki kodlarda önce pwd bulunduğum dizine bakacağım ve sonra map-reduce örneğinin bulunduğu dizinin içini listeleyeceğim. [cloudera@quickstart ~]\$ pwd /home/cloudera [cloudera@quickstart […]
Apache Oozie Nedir? Nasıl Kullanılır? Örnek Java Uygulaması Bölüm-3/3
![]()
İkinci yazımızın hemen ardından Apache Oozie yazımızın üçüncüsüne devam ediyoruz. Yazı uzayınca hafıza körelmiş olabilir Önce hangi dizindeyiz pwd ile bakalım: [cloudera@quickstart java-main]\$ pwd /home/cloudera/oozie_ornekler/examples/apps/java-main Job.properties dosyasını düzenlemek Şimdi nano editörü ile job.properties dosyasının içine girip değişikliklerimizi yapalım. (Siz vi, vim vb. başka editör kullanabilirsiniz) [cloudera@quickstart java-main]\$ sudo nano job.properties nameNode=hdfs://quickstart.cloudera:8020 jobTracker=quickstart.cloudera:8032 queueName=default examplesRoot=examples oozie.wf.application.path=\${nameNode}/user/\${user.name}/\${examplesRoot}/apps/java-main Beşinci […]
Apache Oozie Nedir? Nasıl Kullanılır? Örnek Java Uygulaması Bölüm-2/3
![]()
Oozie yazı dizimizin ikincisine devam ediyoruz. İlk yazıda Oozie hakkında bilgi vermiş, Oozie servisini başlatmış ve examples dosyasını incelemiştik. Şimdi java main örneğini uygulayalım. Bakalım java-main dizini altında neler var neler yok: [cloudera@quickstart oozie_ornekler]\$ cd examples/apps/java-main/ [cloudera@quickstart java-main]\$ ls -ltr total 12 -rw-r–r– 1 1106 4001 1631 Mar 23 2016 workflow.xml -rw-r–r– 1 1106 4001 […]
Apache Oozie Nedir? Nasıl Kullanılır? Örnek Java Uygulaması Bölüm-1/3
![]()
Oozie nedir? Ne işe yarar? Hadoop sistemindeki yeri nedir? Hadoop en yaygın büyük veri platformu olarak piyasadaki öncülüğünü devam ettirmektedir. Hadoop ekosistemi sürekli büyümekte ve yeni ihtiyaçlar için yeni projeler ortaya çıkmakta mevcut projeler ise sürekli iyileşmekte ve gelişmektedir. Apache Oozie sürekli büyüyüp gelişen bu sistemde, yerine getirdiği rol ile önemini korumaktadır. Çünkü sistem büyüdükçe […]
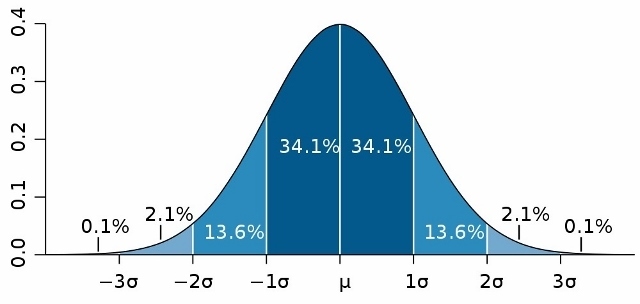
Varyans, Kovaryans ve Standart Sapma Nedir? Örneklerle Açıklama
![]()
Bu yazımda istatistiğin temel kavramlarından varyans, kovaryans ve standart sapmadan bahsetmek istiyorum. Formal bir istatistik eğitimine sahip olmayan biri olarak bu kavramları anlamakta zorlanmıştım, şimdi de ne kadar anlıyorum o da ayrı bir konu. Böyle basit kavramlardan bahsetme amacım, benim gibi öğrenme güçlüğü çeken insanların konuyu örneklerle rahatça anlayabilmelerini sağlamak. Mesela bir seri diyeceğiz birazdan, […]
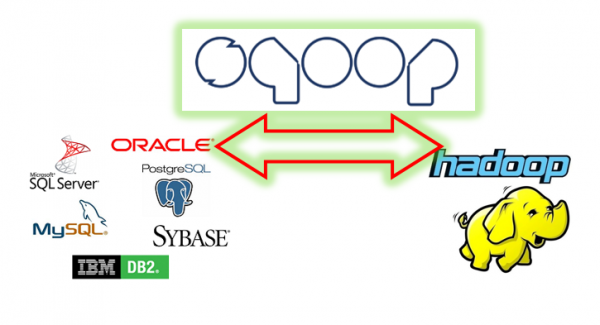
Apache Sqoop Notları (Sqoop Giriş ve Sqoop Import)
![]()
Sqoop Giriş Merhabalar. Bu yazımda Sqoop User Guide 1.4.6 sürümü referans alarak Sqoop hakkında bilgi vermeye çalışacağım. Yazıda HDFS ve RDBMS üzerinde duracağım mainframe veri setinden bahsetmeyeceğim. Sqoop adını SQL ve Hadoop kelimelerinin evliliğinden almış. İşlevi de aslında adının içinde gizli. SQL’den Hadoop’a bir köprüdür Sqoop, yani ilişkisel veri tabanlarından HDFS’e. Bunu yapabilmek için MapReduce […]
Büyük Veri Ön-İşleme (Makale Notları)

![]()
Bu yazımızda Big Data Analytics dergisinde 2016 yılında Garcia vd. (2016) tarafından yazılan “Big data preprocessing:methods and prospects“ isimli makale inceleme notlarımı sizlerle paylaşacağım. Makale özeti sayılmaz, birebir çeviri de değil, her şey yazarlara ait değil, içinde benden de bir şeyler var. Ortaya karışık bir şey işte, idare edin 🙂 Bazı kelimelerin Türkçe karşılığı dilimizde […]
Birliktelik Kuralları: Apriori R Uygulama

![]()
Bu yazımızda birliktelik kurallarının en yaygın kullanılan algoritması olan Apriori ile uygulama yapacağız. Birliktelik kurallarından en çok kullanılanı sepet pazar analizidir. A ürününü alan muhtemelen B ürününü de alır. Örneğin; cips alan muhtemelen meşrubat da alır. Biz de bu veri seti üzerinde Apriori algoritmasını kullanarak şu ürünü alan müşteriler şunları da almış diyebileceğiz. setwd(‘Calisma_Dizniniz’) Apriori […]
Basit Bir Örnek ile Birliktelik Kuralları

![]()
“Bunu alan şunları da aldı” önermesini bir çok alışveriş sitesinde görmüşsünüzdür. Ayrıca birliktelik kurallarını anlatırken sürekli örnek verilen bir birlikte satın alma örüntüsü vardır. Bebek bezi ve bira. Ne alaka diyeceksiniz. Ama bu doğrulanmış bir birliktelik. Nesneler arasındaki bağlantıların ortaya çıkarılması ve bir kural olarak belirlenmesi birliktelik kuralıdır. En yaygın birliktelik kuralı alış-veriş alışkanlıklarının incelendiği […]
Hiyerarşik Kümeleme Python Uygulama

![]()
Kümeleme ve hiyerarşik kümelemede ilerlemeye devam ediyoruz. Bu yazımızda Python hiyerarşik kümeleme uygulaması yapacağız. Önce kütüphaneleri ve veri setini yükleyelim: Veri setini buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as plt import pandas as pd import os os.chdir(‘Calisma_Dizniniz’) dataset = pd.read_csv(‘Mall_Customers.csv’) Spyder varialble explorer ekranından veri setimizi görelim. Veriyi Anlamak Yukarıda görülen veri seti […]
Hiyerarşik Kümeleme ve R ile Dendogram Çizmek

![]()
Bir önceki yazımızda hiyerarşik kümelemeden bahsetmiştik. Noktaları ve kümeleri birleştire birleştire tek büyük bir kümeye ulaşmıştık ve bu küme ne işimize yarayacak demiştik. Cevabı dendogramda saklı. Aslında hiyerarşik kümelemede belirlenen adımlar uygulanırken her hareket kaydediliyor ve dendogram oluşturuluyor. Bu yazımızda dendogram ne işe yarar, nasıl oluşturulur, nasıl okunur? sorularının cevabını R ile yapacağımız basit bir […]
Hiyerarşik Kümeleme Giriş

![]()
Hiyerarşik kümeleme de K-Ortalamalar tekniği gibi aslında aynı sonucu hedefliyor fakat, farklı bir yöntemle, taneciklerden bütüne doğru ilerliyor. K-Ortalamalar tekniğinde olduğu gibi küme kullanıcıdan sayısını istemiyor. İki tip hiyerarşik kümeleme yöntemi var: Agglomerative (sözlük karşılığı yığınsal) ve Divisive (bölücü). Agglomerative yöntemde başlangıçta her nokta bir kümedir. Bu nokta, en yakınındaki noktaları toplayarak küçük kümeleri, daha […]
K-Ortalamalar Tekniği (K-Means Clustering) İle Kümeleme: Python Uygulaması

![]()
Daha önceki üç yazıda kümeleme ve K-ortalamalar algoritmasının temel mantığından ve küme sayısını seçme yönteminden bahsettik. Bu yazımızda Python ile K-Ortalamalar tekniğini kullanarak uygulama yapacağız. Önce kütüphaneleri ve veri setini yükleyelim:Veri setini buradan indirebilirsiniz. import numpy as np import matplotlib.pyplot as plt import pandas as pd import os os.chdir(‘Calisma_Dizniniz’) dataset = pd.read_csv(‘Mall_Customers.csv’) Spyder varialble explorer […]